Apa itu relation pada ERD, Mengapa many-to-many tidak baik digunakan pada ERD

JENIS HUBUNGAN UMUM
Sebelumnya kita telah membahas database relasional satu-ke-banyak . Sejauh ini, ini adalah tipe hubungan data paling umum yang kami temui. Kami berdiskusi tentang orang tua dan anak-anak. Catatan induk dapat memiliki banyak catatan anak, namun catatan anak dimiliki oleh satu dan hanya satu catatan induk. Hubungan tersebut ditentukan melalui data. Catatan induk memiliki kunci utama yang ditetapkan ketika catatan dibuat. Catatan anak menampilkan bagian DNA induknya dengan membawa ID induk unik dalam bidang kunci asing. Ketika nilai kunci asing anak cocok dengan nilai kunci utama induknya, kami memiliki tautan antara catatan tersebut.
Jenis hubungan lain juga terjadi. Pada artikel ini, kita akan membahas hubungan database satu-ke-satu dan banyak-ke-banyak.
MEMILIH JENIS HUBUNGAN YANG TEPAT
Mereka yang baru mengenal desain basis data sering kali memiliki gagasan sebelumnya tentang jenis hubungan apa yang cocok untuk sepasang entitas. Sangat mudah untuk mengambil kesimpulan berdasarkan persepsi seseorang tentang bagaimana sebuah bisnis beroperasi. Sebagai pengembang yang berpengalaman dan degil, kami dapat mengatakan dengan pasti bahwa naluri awal Anda sering kali salah.
Hubungan basis data mencerminkan operasi organisasi yang mendasarinya. Dalam banyak hal, Entity Relationship Diagram (ERD) menggambarkan operasi dalam bentuk tabel dan bidang. Sama seperti pembangun rumah yang menggunakan gambar teknik untuk merencanakan rumah yang sesuai dengan kebutuhan pemilik rumah, ERD menggambarkan arsitektur rencana bisnis dan operasi.
Bayangkan, jika Anda mau, ada dua entitas di sistem Anda. Entitas ini adalah Perwakilan Penjualan dan Pelanggan. Banyak desainer baru mungkin dengan cepat menyimpulkan bahwa Perwakilan Penjualan dapat memiliki banyak Pelanggan, namun Pelanggan hanya dimiliki oleh satu Perwakilan Penjualan, seperti yang ditunjukkan di bawah ini:
 Dalam banyak kasus penggunaan, ini adalah hubungan yang tepat antara Tenaga Penjualan dan Pelanggan. Namun, hal ini tentu tidak berlaku di semua skenario.
Dalam banyak kasus penggunaan, ini adalah hubungan yang tepat antara Tenaga Penjualan dan Pelanggan. Namun, hal ini tentu tidak berlaku di semua skenario.
Bayangkan sebuah perusahaan seperti Boeing yang menjual pesawat terbang. Pelanggan mereka adalah maskapai penerbangan besar dan militer – perusahaan seperti American Airlines, Southwest Airlines, Angkatan Darat AS, dan JetBlue.
Pelanggan sebesar ini tentu membutuhkan lebih dari satu Sales Rep. Faktanya, mereka kemungkinan besar memiliki tim Perwakilan Penjualan yang mengerjakan penjualan pesawat bernilai miliaran dolar. Namun setiap Perwakilan Penjualan akan ditugaskan ke satu dan hanya satu Pelanggan, seperti yang ditunjukkan di bawah ini:
 Terakhir, bayangkan sebuah skenario di mana terdapat pendekatan tim terhadap penjualan. Pelanggan dapat membeli dari beberapa Perwakilan Penjualan di tim penjualan, dan Perwakilan Penjualan dapat menjual ke banyak Pelanggan yang berbeda. Ini adalah contoh hubungan banyak ke banyak. Nanti di artikel ini, kita akan membahas penyelesaian hubungan banyak-ke-banyak dengan benar dalam ERD dan Honeycode . Namun untuk saat ini, sadarilah bahwa pola ERD berikut ini juga tepat dan cukup umum.
Terakhir, bayangkan sebuah skenario di mana terdapat pendekatan tim terhadap penjualan. Pelanggan dapat membeli dari beberapa Perwakilan Penjualan di tim penjualan, dan Perwakilan Penjualan dapat menjual ke banyak Pelanggan yang berbeda. Ini adalah contoh hubungan banyak ke banyak. Nanti di artikel ini, kita akan membahas penyelesaian hubungan banyak-ke-banyak dengan benar dalam ERD dan Honeycode . Namun untuk saat ini, sadarilah bahwa pola ERD berikut ini juga tepat dan cukup umum.
Kami berharap mudah untuk melihat bahwa hubungan antara pasangan entitas mana pun tidak memiliki jawaban default. Kita, sebagai desainer, perlu menyadari bahwa hubungan didasarkan pada konteks organisasi. Tugas kami sebagai desainer dan pengembang adalah mengekstrak informasi penting ini dalam diskusi dengan pengguna dan mengelola sistem yang kami rencanakan.
HUBUNGAN SATU-KE-SATU
Meskipun agak jarang terjadi dalam sistem basis data dengan ukuran dan kompleksitas yang dibuat di Honeycode, kami melihat hubungan satu-ke-satu dalam beberapa situasi dalam pengembangan sistem basis data.
Intinya, kami mengatakan satu catatan di tabel "A" terkait dengan satu dan hanya satu catatan di tabel "B". Dan satu record di tabel “B” berhubungan dengan satu dan hanya satu record di tabel “A.” Mungkin juga bahwa record di “A” atau “B” tidak berhubungan dengan record di yang lain. Lebih lanjut tentang ini nanti.
Anda mungkin bertanya pada diri sendiri mengapa tabel-tabel ini tidak digabungkan? Sebenarnya itu pertanyaan yang bagus, dan ada beberapa kasus penggunaan yang menganggap hal ini masuk akal.
Bertahun-tahun yang lalu, kami berurusan dengan klien dengan tabel karyawan yang sangat besar. Ada ribuan karyawan di organisasi ini. Beberapa lusin di antara ribuan memerlukan data yang sangat khusus selain data karyawan secara umum.
Ternyata, informasi tersebut terkait dengan izin keamanan dan cukup sensitif. Karena sangat berhati-hati, perusahaan bersikeras agar informasi ini disimpan dalam database terpisah dengan pengaturan keamanan yang sangat berbeda. Catatan dalam tabel “Info Keamanan” akan ditautkan ke satu dan hanya satu catatan dalam tabel Karyawan. Sejumlah catatan di tabel Karyawan akan ditautkan ke satu dan hanya satu catatan di tabel “Info Keamanan”. Sebagian besar catatan dalam tabel “Karyawan” tidak akan ditautkan ke catatan dalam tabel “Info Keamanan” sama sekali karena orang-orang tersebut tidak terlibat dalam pekerjaan rahasia.
NORMALISASI DATA
Selain implikasi keamanan, ada alasan lain mengapa data scientist cenderung menguraikan informasi keamanan ke dalam tabel terpisah.
Kita akan menjadi sedikit “culun” di sini, jadi pertahankan keyboard dan mouse Anda. Dalam desain database tingkat lanjut, terdapat aturan dan persyaratan normalisasi data. Ini terkait dengan teori himpunan dalam matematika dan digunakan untuk memberikan efisiensi data kedua dari belakang. Sebenarnya, mereka bisa menjadi sangat kompleks, dan beberapa benar-benar mencapai normalisasi tingkat lanjut.
Perusahaan besar dengan sistem penyimpanan data yang besar sudah lama menyadari bahwa mereka dapat menghemat uang untuk penyimpanan data dengan menerapkan desain data yang efisien. Bayangkan sebuah perusahaan besar seperti Amazon dan berapa banyak data yang disimpan untuk pesanan masa lalu dan sekarang serta produk yang terdaftar untuk dijual.
Beberapa tahun yang lalu, kami bekerja sama dengan bank besar untuk mencari solusi tingkat departemen. Kami menghadiri pertemuan di ruang konferensi besar yang memiliki dinding panjang yang ditutupi ERD besar selama pertemuan tersebut. Ternyata ERD ini hanya digunakan untuk operasional kartu kredit mereka saja. Diagram tersebut memiliki ratusan entitas dan serangkaian hubungan terdefinisi yang sangat kompleks. Tentu saja, bank ini mempekerjakan para Ph.D. di bidang matematika dan ilmu data, dan tugas mereka adalah meningkatkan efisiensi dan meminimalkan redundansi. Dalam diagram ini terdapat banyak hubungan satu-ke-satu.
Kabar baiknya adalah kita, sebagai pengembang Amazon Honeycode, kemungkinan besar tidak akan menghadapi tingkat kerumitan seperti itu. Keputusan kami akan didasarkan pada kebutuhan dan logika bisnis, bukan matematika yang rumit.
CONTOH HUBUNGAN SATU-KE-SATU
Baru-baru ini kami bekerja dengan klub olahraga kelas atas. Mereka mencari sistem untuk melacak banyak aspek bisnis mereka, termasuk anggota, biaya keanggotaan, fasilitas, program, dan banyak lagi.
Di fasilitas ini, mereka menyediakan loker bagi anggotanya. Pada awalnya, hal ini tampak semudah memberikan nomor loker untuk setiap anggota. Cukup sederhana, bukan?
Namun saat kami menyelidiki lebih lanjut, kami menemukan bahwa ada informasi tambahan yang dikumpulkan di setiap loker. Ini termasuk nomor loker, ukuran, lokasi, dan kombinasi kunci yang dipasang.
Bayangkan sejenak informasi ini disimpan sebagai bagian dari tabel Anggota. Kami hanya menambahkan beberapa bidang ke tabel Anggota untuk tujuan itu.
Inilah tantangan dengan jenis struktur data gabungan tersebut. Jika fasilitas menambahkan sejumlah loker baru yang belum ditetapkan ke anggota, di manakah data tersebut akan disimpan? Apakah pengguna akan membuat catatan anggota baru yang kosong agar dapat menyimpan detail loker? Selain itu, jika seorang anggota meninggalkan klub dan anggota tersebut dihapus dari tabel “Anggota”, itu juga akan menghapus informasi loker.
Dalam terminologi basis data, masalah ini dikenal sebagai anomali penyisipan dan anomali penghapusan. Banyak orang yang baru mengenal struktur data menjadi korban masalah ini. Itulah alasan kami ingin melacak satu dan hanya satu jenis data dalam sebuah tabel. Kami ingin menghindari struktur rekaman gabungan yang mana beberapa orang, tempat, objek, atau peristiwa berbeda disimpan dalam tabel yang sama.
Dalam hal ini, kami akan membuat dua tabel terpisah untuk Anggota dan Loker. Karena seorang anggota diberikan satu dan hanya satu loker, dan satu loker diberikan hanya kepada satu anggota, kita mempunyai hubungan satu-ke-satu.
MENGAPA MENGGUNAKAN HUBUNGAN SATU-KE-SATU
Kami telah memberikan dua contoh hubungan satu lawan satu. Dalam satu kasus, hal ini bertujuan untuk meminimalkan penyimpanan data dan menyediakan langkah-langkah keamanan terpisah. Di sisi lain, kami ingin membuat model data yang memungkinkan pembuatan data yang benar-benar terpisah dan unik.
Namun, kami ingin memberi masukan bahwa hubungan ini mudah disalahgunakan. Pastikan untuk tidak menerapkannya di tempat yang tidak diperlukan dan jangan membuat ERD yang terlalu rumit di tempat yang tidak diperlukan.
Misalnya, berdasarkan pembacaan aturan normalisasi data yang sangat ketat, seseorang mungkin merasa diperlukan hubungan satu lawan satu. Namun perlu diingat juga bahwa banyak dari peraturan yang sangat ketat ini dibuat pada saat penyimpanan komputer sangat mahal. Jumlah penyimpanan yang kita miliki di ponsel saat ini akan menelan biaya puluhan juta dolar 50 tahun yang lalu.
Salah satu aturan normalisasi mengatakan bahwa atribut (bidang) hanya boleh dimiliki oleh tabel jika ada nilai untuk setiap instance (catatan). Kita tahu bahwa kebanyakan orang memiliki nomor telepon rumah, namun ada pengecualian. Berdasarkan interpretasi yang ketat, kami akan menempatkan nomor telepon rumah dalam file satu-ke-satu yang terpisah.
Kami pikir itu berlebihan di zaman sekarang ini. Kurangnya nilai juga bisa menyampaikan makna. Dalam arti yang aneh, tidak adanya nilai memberi tahu kita bahwa ia tidak ada. Atau kita belum tahu nilainya.
Misalnya, tidak adanya nomor telepon rumah dapat memberi tahu kita bahwa orang tersebut tidak memiliki nomor rumah. Hal ini menjadi semakin umum terjadi pada telepon seluler yang ada di mana-mana. Atau bisa juga memberi tahu kita bahwa kita belum memiliki datanya.
Berhati-hatilah dalam menggunakan hubungan satu lawan satu. Mereka memang mempunyai nilai dan penting dalam keadaan tertentu. Gunakan dengan bijak dan hati-hati jika memungkinkan. Tapi jangan terbawa suasana.
HUBUNGAN BANYAK KE BANYAK
Seperti yang kami sebutkan sebelumnya, hubungan banyak ke banyak cukup umum dalam desain database. Kami sering menemukannya hanya setelah berdiskusi dengan pengguna sistem dan manajemen. Dalam banyak kasus, hal tersebut tidak terlihat jelas sampai kasus penggunaan ditentukan dan kebutuhan bisnis diselidiki.
Beberapa hubungan banyak-ke-banyak terlihat jelas. Ada contoh klasik yang kami gunakan dalam pengajaran hubungan yang melibatkan Siswa dan Kelas.
Secara intuitif kita tahu bahwa seorang Siswa pada umumnya akan mengambil banyak Kelas. Dan suatu Kelas kemungkinan besar akan memiliki banyak Siswa. Jadi banyak ke banyak, seperti yang ditunjukkan di bawah ini.
 Pertanyaannya adalah, bagaimana kita menerapkan hubungan banyak ke banyak dalam sistem Honeycode kita?
Pertanyaannya adalah, bagaimana kita menerapkan hubungan banyak ke banyak dalam sistem Honeycode kita?
Banyak pengembang pertama kali mencoba menempatkan bidang kunci asing di tabel Siswa dan Kelas untuk mengatasi kebutuhan data ini. Ini masuk akal bagi orang baru karena kami menggunakan kunci asing untuk menyelesaikan hubungan satu-ke-banyak. Namun, hal itu tidak akan berhasil karena berbagai alasan.
Mari kita visualisasikan masalahnya sejenak. Kami memiliki tabel Siswa dan tabel Kelas, seperti yang ditunjukkan di bawah ini:
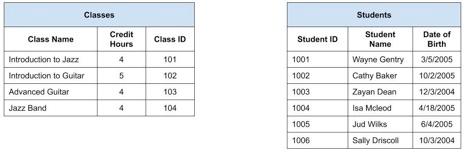
Bayangkan informasi ini dicetak pada selembar kertas besar dan digantung di dinding. Panitera sekolah ingin melihat diagram yang menunjukkan Siswa mana yang terdaftar di Kelas mana.
Saya pikir sebagian besar akan melakukannya dengan menarik garis antara Kelas dan Siswa. Dengan mengikuti baris-baris tersebut, kita dapat melihat siapa yang tertaut ke setiap Kelas, atau Kelas mana yang didaftarkan oleh setiap Siswa, sebagai berikut:
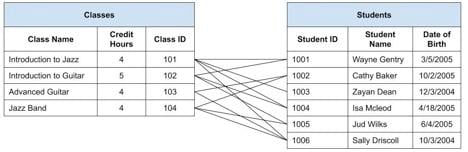 Meskipun agak berantakan dan sulit untuk diikuti, rangkaian garis ini secara akurat menggambarkan hubungan banyak-ke-banyak antar entitas. Setiap Siswa dapat didaftarkan dalam satu atau lebih Kelas. Setiap Kelas dapat memiliki satu atau lebih Siswa yang terdaftar. Ikuti saja garis dari kedua sisi. Setiap baris mewakili satu Siswa yang terdaftar dalam satu Kelas. Hitung antreannya, dan Anda tahu berapa banyak pendaftaran kelas yang ada.
Meskipun agak berantakan dan sulit untuk diikuti, rangkaian garis ini secara akurat menggambarkan hubungan banyak-ke-banyak antar entitas. Setiap Siswa dapat didaftarkan dalam satu atau lebih Kelas. Setiap Kelas dapat memiliki satu atau lebih Siswa yang terdaftar. Ikuti saja garis dari kedua sisi. Setiap baris mewakili satu Siswa yang terdaftar dalam satu Kelas. Hitung antreannya, dan Anda tahu berapa banyak pendaftaran kelas yang ada.
Jadi bagaimana kita merepresentasikan garis-garis tersebut dalam data? Jawabannya sangat mudah. Ketika kita mempunyai hubungan banyak-ke-banyak, kita menambahkan tabel gabungan ketiga di tengah untuk melacak semua tautan ini. Dalam kasus di atas, kita mungkin memiliki tabel bernama Pendaftaran. Intinya, kami mengubah garis dalam diagram menjadi catatan dan data.
 Perhatikan hubungan banyak-ke-banyak telah diubah menjadi sepasang hubungan satu-ke-banyak pada Pendaftaran entitas baru kita. Lebih lanjut, perhatikan bahwa Pendaftaran adalah sisi “banyak” dari kedua hubungan dengan dua tanda bahaya yang melekat padanya. Seperti yang telah dibahas di artikel sebelumnya , kaki gagak melambangkan sisi kekanak-kanakan dalam suatu hubungan. Pendaftaran adalah turunan dari Siswa dan Kelas, sehingga Pendaftaran akan memiliki dua kunci asing, masing-masing satu untuk Siswa dan Kelas.
Perhatikan hubungan banyak-ke-banyak telah diubah menjadi sepasang hubungan satu-ke-banyak pada Pendaftaran entitas baru kita. Lebih lanjut, perhatikan bahwa Pendaftaran adalah sisi “banyak” dari kedua hubungan dengan dua tanda bahaya yang melekat padanya. Seperti yang telah dibahas di artikel sebelumnya , kaki gagak melambangkan sisi kekanak-kanakan dalam suatu hubungan. Pendaftaran adalah turunan dari Siswa dan Kelas, sehingga Pendaftaran akan memiliki dua kunci asing, masing-masing satu untuk Siswa dan Kelas.
Kami menjelaskan bahwa di Pendaftaran, kami akan mengubah garis dari diagram di atas menjadi data. Setiap baris dimulai pada catatan siswa dan berakhir pada catatan kelas. Setiap baris dalam tabel Siswa mempunyai ID Siswa yang unik, dan Kelas memiliki ID Kelas yang unik. Setiap baris kemudian ditentukan oleh ID Siswa awal dan ID Kelas akhir. Setiap pendaftaran akan membawa ID catatan induknya, baik Siswa maupun Kelas, seperti yang ditunjukkan di bawah ini.
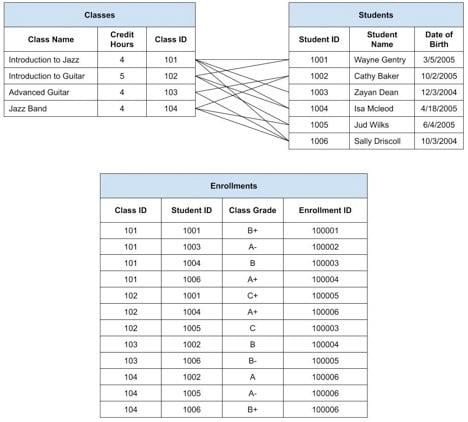 Kami telah meninggalkan garis antara Siswa dan Kelas untuk memudahkan melihat bagaimana setiap baris diterjemahkan ke dalam baris dalam tabel Pendaftaran. Perhatikan juga bahwa tabel Pendaftaran dapat memiliki atribut lain. Kami memiliki atribut Kelas Kelas. Jika dipikir secara rasional, nilai bukanlah atribut dari Siswa, atau Kelas. Ini adalah karakteristik Siswa di Kelas dan karenanya termasuk dalam Pendaftaran. Kita bisa membayangkan atribut lain seperti catatan guru, jumlah ketidakhadiran, atau biaya sekolah untuk setiap siswa.
Kami telah meninggalkan garis antara Siswa dan Kelas untuk memudahkan melihat bagaimana setiap baris diterjemahkan ke dalam baris dalam tabel Pendaftaran. Perhatikan juga bahwa tabel Pendaftaran dapat memiliki atribut lain. Kami memiliki atribut Kelas Kelas. Jika dipikir secara rasional, nilai bukanlah atribut dari Siswa, atau Kelas. Ini adalah karakteristik Siswa di Kelas dan karenanya termasuk dalam Pendaftaran. Kita bisa membayangkan atribut lain seperti catatan guru, jumlah ketidakhadiran, atau biaya sekolah untuk setiap siswa.
Di Honeycode, kita akan membuat ketiga tabel seperti yang ditunjukkan di atas. Seperti yang telah dibahas sebelumnya, Rowlinks di Honeycode dibuat di tabel anak ke tabel induk. Dalam contoh ini, kita akan membuat satu Rowlink Honeycode dari Pendaftaran ke Siswa, dan Rowlink Honeycode lainnya dari Pendaftaran ke Kelas.
Satu hal lagi yang perlu diperhatikan, setiap baris dalam tabel Pendaftaran juga memiliki atribut kunci utama yang disebut ID Pendaftaran. Kunci utama digunakan untuk menautkan catatan anak ke catatan induk, dan Anda mungkin bertanya-tanya apakah kami memerlukan kunci utama dalam Pendaftaran karena tidak memiliki tabel anak terkait. Praktik terbaik menunjukkan bahwa kita harus memiliki kunci utama untuk baris di semua tabel. Ada penggunaan kunci utama lainnya yang lebih canggih yang berada di luar cakupan artikel ini. Ada kalanya kita perlu mengidentifikasi ID unik suatu baris selama skenario otomatisasi atau integrasi.
Kabar baiknya bagi kami adalah Honeycode menangani pembuatan kunci utama secara otomatis dan tidak terlihat. Itu ada di sana bahkan jika Anda tidak melihatnya. Dan ini sangat bermanfaat dalam beberapa bidang fungsi utama.
KETIKA SATU-KE-BANYAK BERUBAH MENJADI BANYAK-KE-BANYAK
Ada pola kasus penggunaan umum yang kami lihat yang dapat mengubah jenis hubungan yang digunakan dalam desain sistem. Berikut ini adalah beberapa contohnya.
Kunci untuk membangun sistem ERD dan Honeycode yang sukses adalah komunikasi. Kami tidak dapat membantu memecahkan kebutuhan otomatisasi tanpa sepenuhnya mengeksplorasi dan memahami cara bisnis beroperasi.
Dalam banyak hal, membangun sistem adat seperti seorang penjahit yang membuat pakaian adat. Dimulai dari pengukuran ekstensif, pilihan model jaket dan celana, bahan yang digunakan, dan banyak lagi. Penjahit merancang setelan sesuai gaya tubuh kita, seperti halnya perangkat lunak khusus yang dibuat berdasarkan kebutuhan dan operasi bisnis.
Anggaplah kita sedang membangun sistem entri pesanan yang relatif sederhana di mana pelanggan dapat memesan barang dari situs web kita. Setiap pelanggan dapat memiliki beberapa alamat pengiriman yang dilampirkan ke akun mereka, dan mereka memilih salah satu alamat pengiriman untuk pesanan tersebut saat pembayaran. Dalam hal ini, kita akan memiliki ERD yang berisi hubungan satu-ke-banyak antara entitas Alamat Pengiriman dan entitas Pesanan. Pesanan dikirim ke satu dan hanya satu alamat, namun Alamat Pengiriman mungkin terkait dengan banyak Pesanan berbeda.
 Namun, dalam diskusi lebih lanjut dengan klien, terlihat bahwa terkadang pelanggan mengirimkan pesanan ke lebih dari satu alamat. Misalnya, pelanggan dapat memesan sejumlah rangkaian bunga serupa sebagai hadiah liburan dan masing-masing dikirimkan ke alamat yang berbeda. Dalam hal ini, suatu Pesanan dapat memiliki lebih dari satu Alamat Pengiriman, dan Alamat Pengiriman dapat digunakan pada lebih dari satu Pesanan. Jadi hubungan kita menjadi banyak ke banyak, seperti gambar di bawah ini.
Namun, dalam diskusi lebih lanjut dengan klien, terlihat bahwa terkadang pelanggan mengirimkan pesanan ke lebih dari satu alamat. Misalnya, pelanggan dapat memesan sejumlah rangkaian bunga serupa sebagai hadiah liburan dan masing-masing dikirimkan ke alamat yang berbeda. Dalam hal ini, suatu Pesanan dapat memiliki lebih dari satu Alamat Pengiriman, dan Alamat Pengiriman dapat digunakan pada lebih dari satu Pesanan. Jadi hubungan kita menjadi banyak ke banyak, seperti gambar di bawah ini.
 Pertama dan terpenting, perubahan ke banyak-ke-banyak ini lebih rumit daripada yang kami tunjukkan di sini. Perubahan ini memerlukan reorganisasi ERD yang cukup besar. Ada efek riak yang cukup luas yang diperlukan untuk kasus penggunaan yang tidak lazim namun penting.
Pertama dan terpenting, perubahan ke banyak-ke-banyak ini lebih rumit daripada yang kami tunjukkan di sini. Perubahan ini memerlukan reorganisasi ERD yang cukup besar. Ada efek riak yang cukup luas yang diperlukan untuk kasus penggunaan yang tidak lazim namun penting.
Itu sebabnya kami ingin mendapatkan ERD yang benar pada kali pertama. Terkadang perubahan pada ERD relatif sederhana. Namun ada pula yang memerlukan perubahan besar. Jika kami sudah membangun sistem bisnis di Honeycode, kami akan membuat beberapa perubahan pengembangan yang menantang.
Ini sering disebut sebagai kasus pinggiran atau tepi. Ini adalah kejadian yang tidak sering terjadi namun tetap perlu diperhatikan. Kami hanya menemukan kasus-kasus kecil melalui analisis menyeluruh terhadap sistem dan percakapan berulang-ulang dengan pengguna dan manajemen. Seringkali pengguna lebih mengetahui kasus-kasus pinggiran ini karena mereka berada di garis depan dalam menangani pelanggan serta pertanyaan dan masalah mereka.
Seperti halnya semua keputusan hubungan, kita harus memeriksa setiap perubahan dengan hati-hati untuk melihat apakah ada kebutuhan. Kita dapat mengubah satu-ke-banyak menjadi banyak-ke-banyak bila tidak benar-benar diperlukan. Jika ada kasus pinggiran atau edge yang sangat jarang terjadi, kami mungkin mencari solusi untuk keadaan tersebut.
Asumsikan kita hanya memiliki satu contoh dalam setahun pelanggan yang membutuhkan beberapa alamat pengiriman. Masuk akal untuk meminta pelanggan tersebut melakukan pemesanan terpisah, masing-masing dengan alamat pengiriman tunggal. Hal ini memang kurang ideal, namun dalam pengembangan perangkat lunak, kita perlu mempertimbangkan biaya tambahan dan kompleksitas perubahan serta manfaat yang diperoleh.
MEMBUNGKUS
Harap diingat bahwa membuat ERD berarti membuat peta jalan untuk struktur sistem database Anda. Penambahan atau modifikasi selanjutnya bisa jadi mudah atau sangat menantang dan memerlukan banyak usaha. Yang terbaik adalah melakukannya dengan benar pada kali pertama.
Ada banyak kesamaan antara mendesain rumah dan mendesain database. Bayangkan semua orang menyetujui rencana desain rumah. Pembangun membuat rumah persis seperti yang ditentukan dalam rencana. Saat klien masuk untuk pertama kalinya, mereka meminta beberapa perubahan kecil.
Pertama, mereka ingin warna kamar tidur diubah. Hal ini mirip dengan membuat perubahan pada antarmuka pengguna suatu sistem dan umumnya relatif mudah dilakukan. Namun kemudian klien menyadari bahwa dapurnya tidak mendapat sinar matahari pagi, sehingga mereka ingin dapur dipindahkan dari sisi barat rumah ke sisi timur. Sekarang saya rasa semua orang menyadari bahwa perubahan besar memerlukan banyak dekonstruksi dan rekonstruksi. Oh, sebagai tambahan, klien memutuskan untuk mendorong fondasi sejauh 4 kaki lagi ke setiap arah. Pada titik ini, mungkin akan lebih mudah untuk merobohkan struktur yang sudah ada dan membangunnya dari awal. Dan ya, hal itu juga terjadi dalam pembangunan sistem basis data. Terkadang klien tidak dapat benar-benar membayangkan apa yang mereka minta, namun mereka tahu itu bukanlah apa yang mereka inginkan ketika mereka melihatnya.
Untungnya, Honeycode adalah alat tanpa kode. Dari pengalaman pribadi, kita dapat mengatakan bahwa perubahan signifikan lebih sederhana di lingkungan tanpa kode dibandingkan di platform rendah dan pro-kode. Daripada menulis kode untuk mengubah urutan objek pada formulir, kita bisa mengklik dan menyeretnya. Sangat mudah untuk membuat formulir baru untuk menggantikan formulir yang sudah ada. Dan karena Honeycode menangani banyak hubungan relasional di belakang layar, pekerjaan kita akan berkurang ketika diperlukan perubahan.
Terlepas dari kompleksitas sistem Anda atau alat yang Anda gunakan untuk membangunnya, pastikan untuk meluangkan waktu untuk membuat rencana sebelum mengembangkan konkret.


Tidak ada komentar:
Posting Komentar